
|
| || Home || Projects || Publications || Members || |
| PhenoMining | SNRS | ISP | CoXML | KMeX | KMeD | CoBase | Data Mining |
KMeX: A Knowledge-Based Approach for Scenario-Specific Medical Free Text RetrievalProject funded in part by NIC/NIH Grant # 4442511-33780
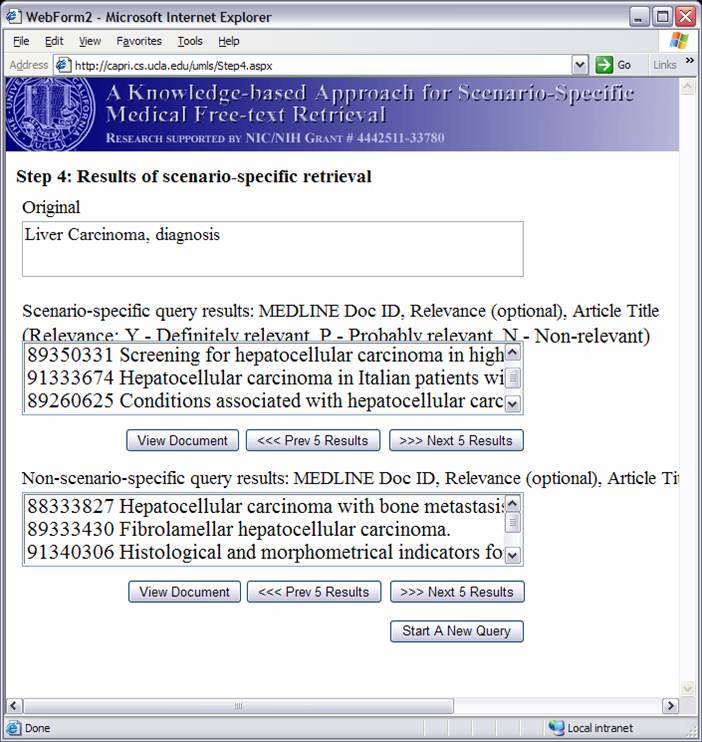
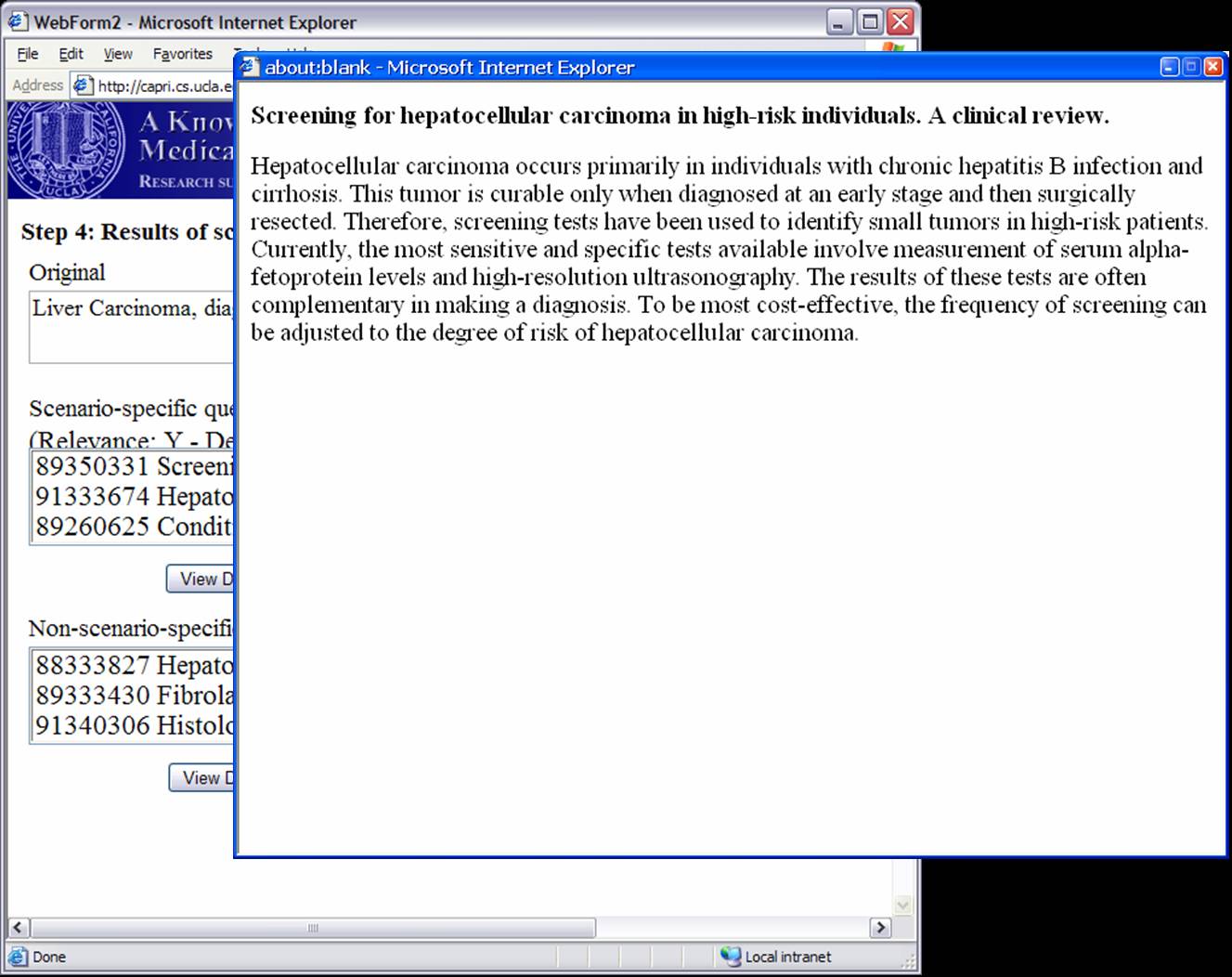
Knowledge-based Inference Techniques to Ensure the Security of Database Content.With the rapid growth of web applications, free-text document retrieval becomes an important aspect of information technology. Traditional information retrieval systems have several shortcomings. In this project, we study the following innovative techniques to remedy these problems and to improve document retrieval performance. Extracting Key Concepts from Free Text for Indexing. A software tool called IndexFinder has been developed that can extract key concepts from free text. IndexFinder permutes adjacent terms in each sentence in a document to generate a set of valid concepts as defined by the controlled vocabulary in the knowledge source (e.g., UMLS). This is much more effective than the conventional natural language processing (NLP) approach. Syntactic and semantic filters are used to eliminate irrelevant concepts from permuting terms. Effective semantic filtering techniques will be developed for the IndexFinder to improve the accuracy of the indexing. Phrase-based Vector Space Model (VSM) Vector Space Models (VSM) are commonly used to measure the similarity between a query and a document. Traditional stem-based VSM cannot match terms in the query with those used in the documents that have a similar meaning but different expressions. We developed a knowledge-based, phrase-based VSM [Mao02], which identifies terms with similar meanings and represents them based on both concepts and stems. As a result, phrase-based VSM yields significantly better retrieval performance than the stem-based VSM. Topic-Oriented Directory Hierarchy. One of the difficulties in designing a directory system for free text documents is their representation unit. Topics/subtopics are proposed as the building blocks for the directory system. The topics are derived by mining frequently co-occurring key document concepts extracted from the IndexFinder. Domain knowledge as well as query patterns are used to guide construction of the topic-subtopic hierarchy. Data-mining will be used to generate topics and subtopics from the set of key concepts of documents. Knowledge-Based Query Expansion. A query may be appended with additional terms so that the expanded query has a higher probability of matching the terms in relevant documents. Traditional expansion techniques append statistically related terms that may not be scenario-specific. A knowledge-based expansion approach is proposed that appends terms related to the query scenario. Since knowledge sources are often incomplete, a knowledge acquisition methodology shall be developed for acquiring missing knowledge from domain experts. 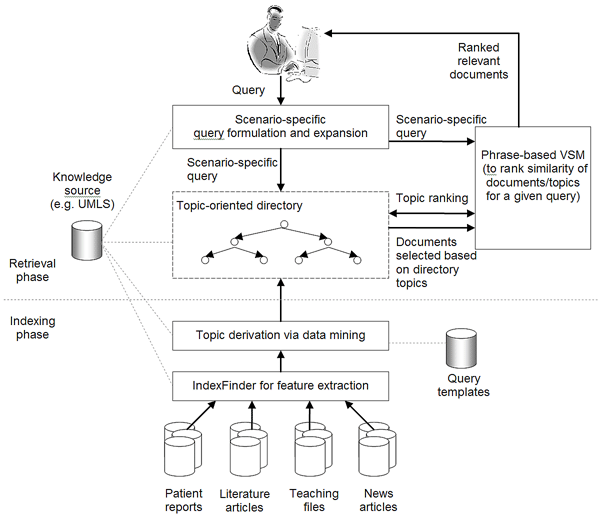 We are implementing and integrating the three proposed techniques in a test bed to provide scenario-specific free-text retrieval. This system provides the capability to retrieve many types of medical free-text documents, e.g., patient clinical reports, medical literature articles, etc. During the indexing phase, IndexFinder will first extract key concepts and normalize them into standard terms as defined in the knowledge source (e.g., UMLS). Topics and subtopics are derived by mining the frequently co-occurring features extracted from the documents. With the aid of the knowledge source and users query patterns, a topic-oriented directory system can be constructed. During the retrieval phase, the query expansion module appends the user query with scenario-specific terms. The directory system selects the most relevant topics that match the expanded query. Documents that belong to those topics are submitted to the module which ranks the documents based on their similarity to the query via the phrase-based Vector Space Model (VSM). The ranked relevant documents are returned to the user. A Screenshot Tour of the KMEX System:Let us now use the actual KMEX screenshots to walk through the various functions and capabilities of the KMEX system. Please note that some pictures are quite large. Please be prepared to wait a bit if you don't have a fast network connection. Example 1: 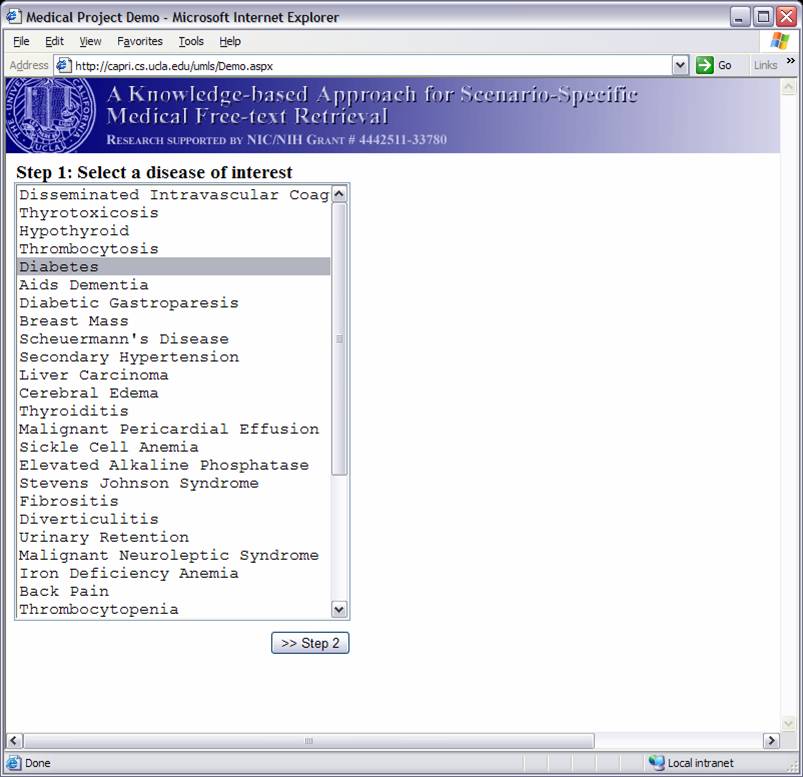 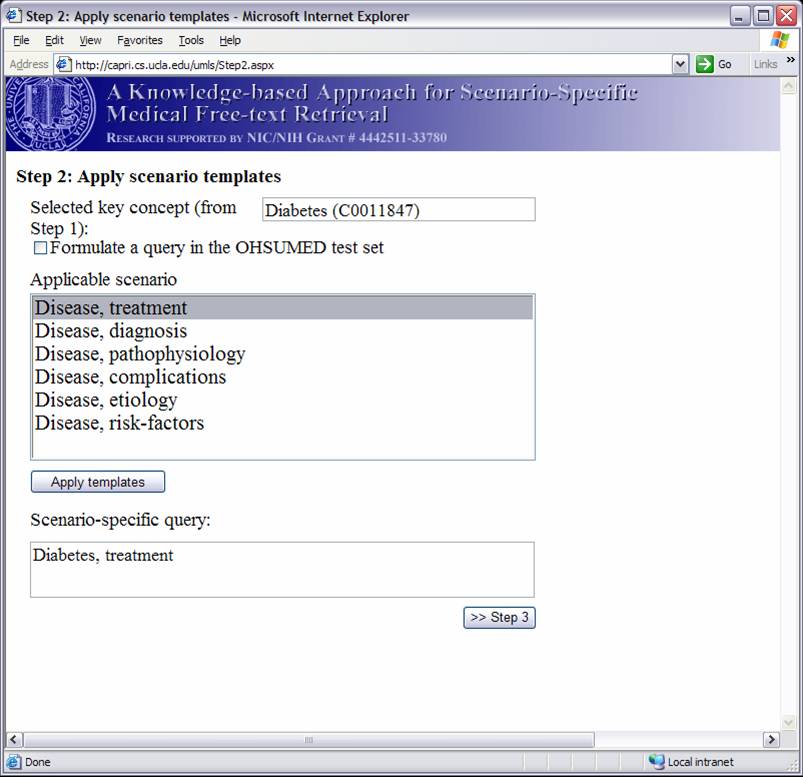 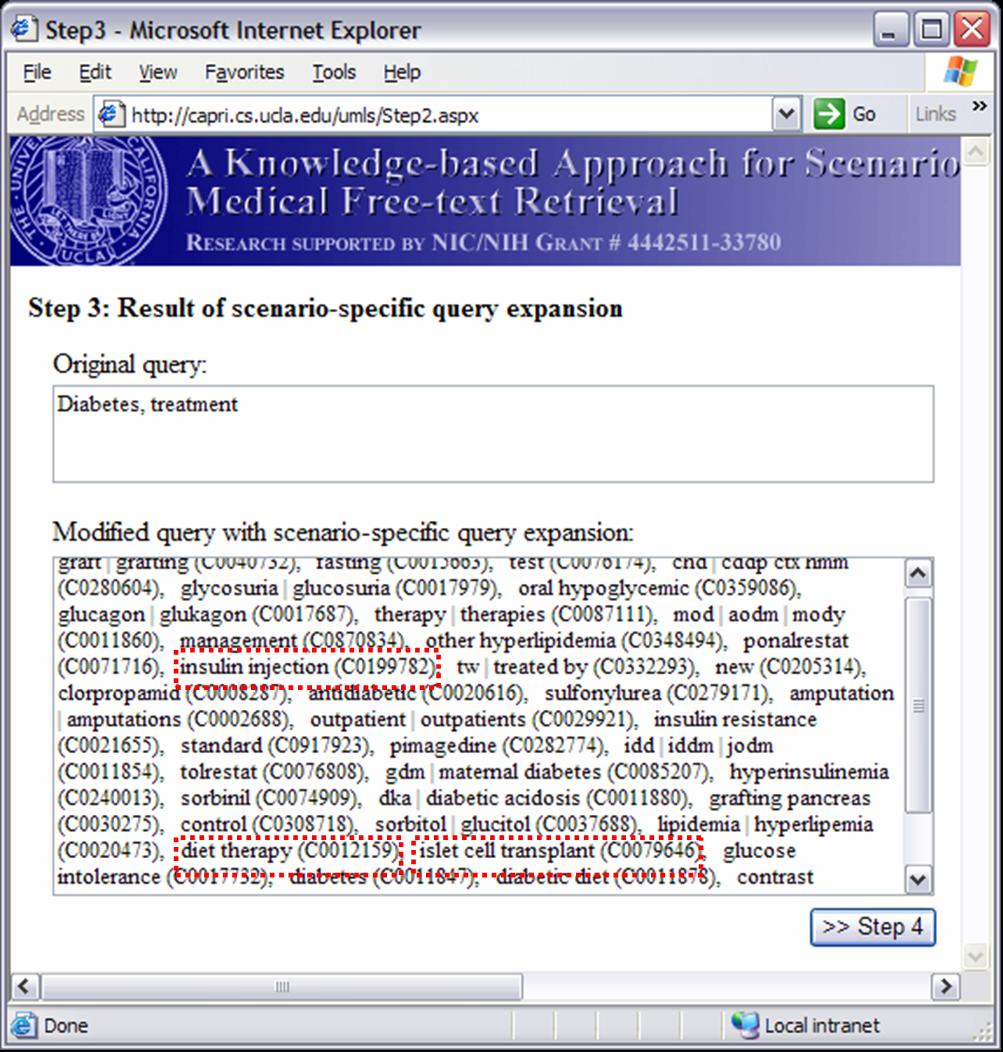 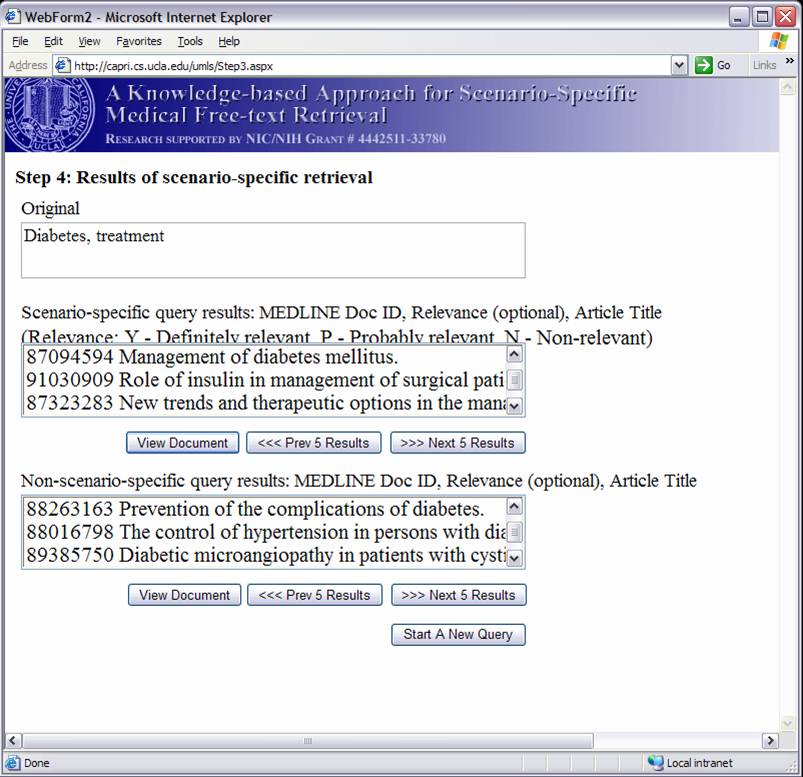 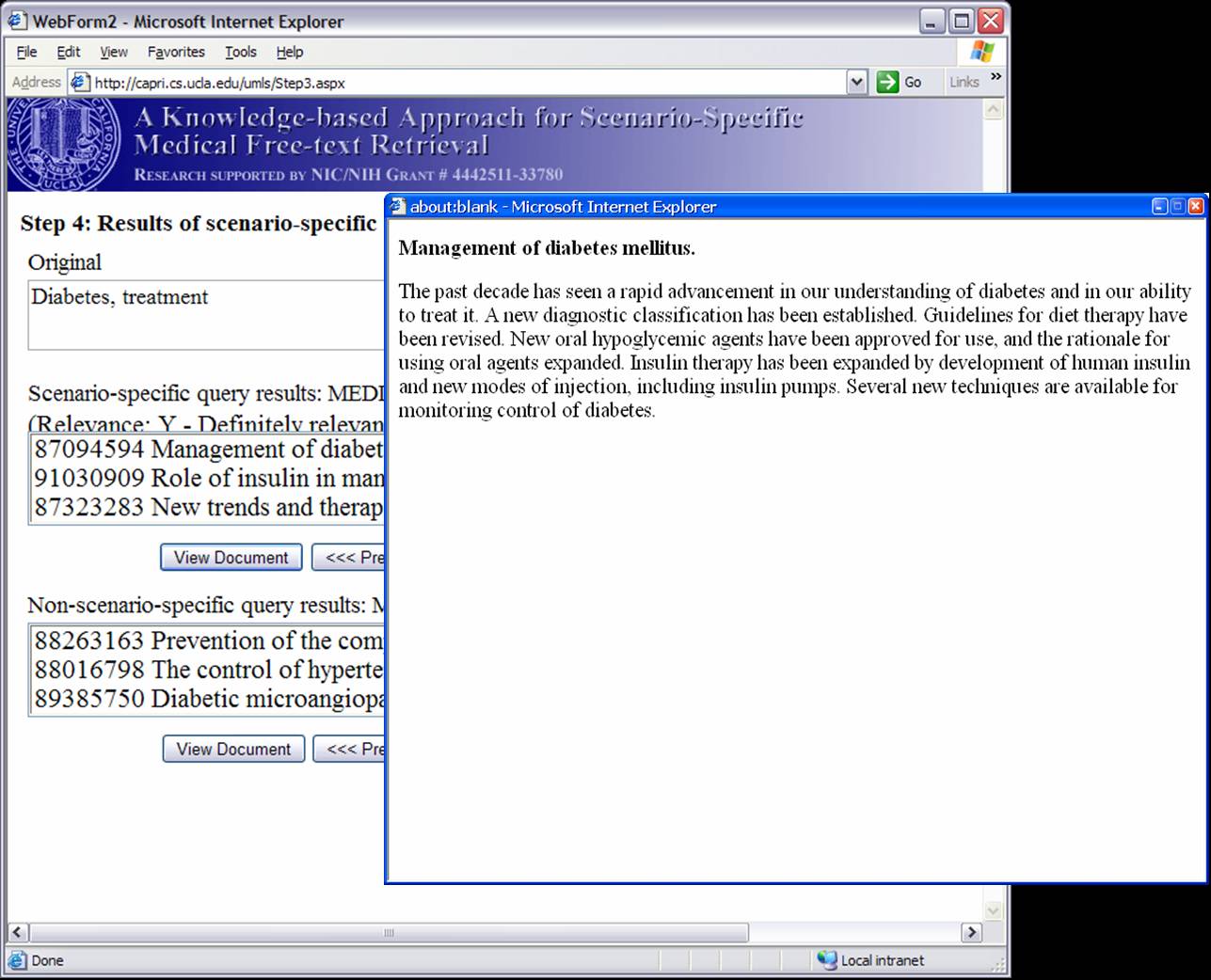 Example 2: 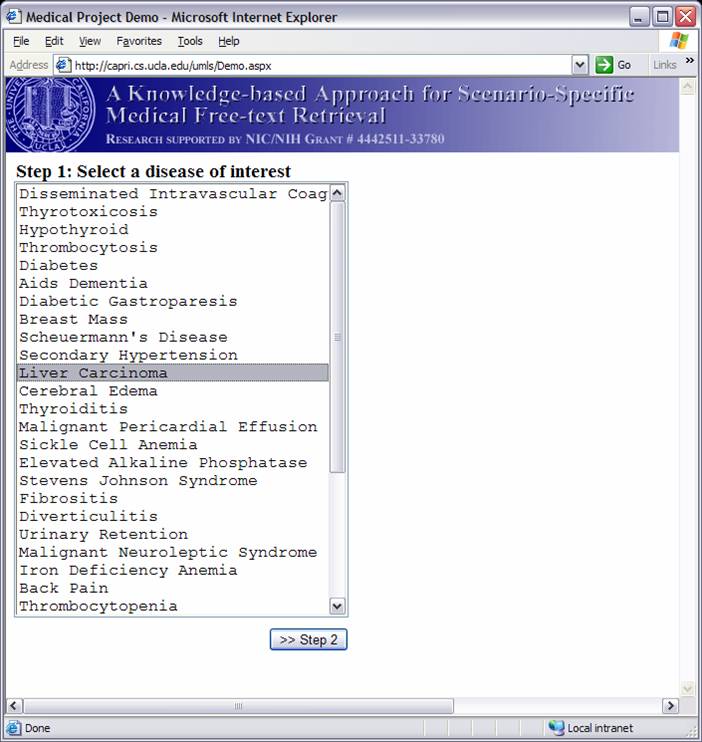 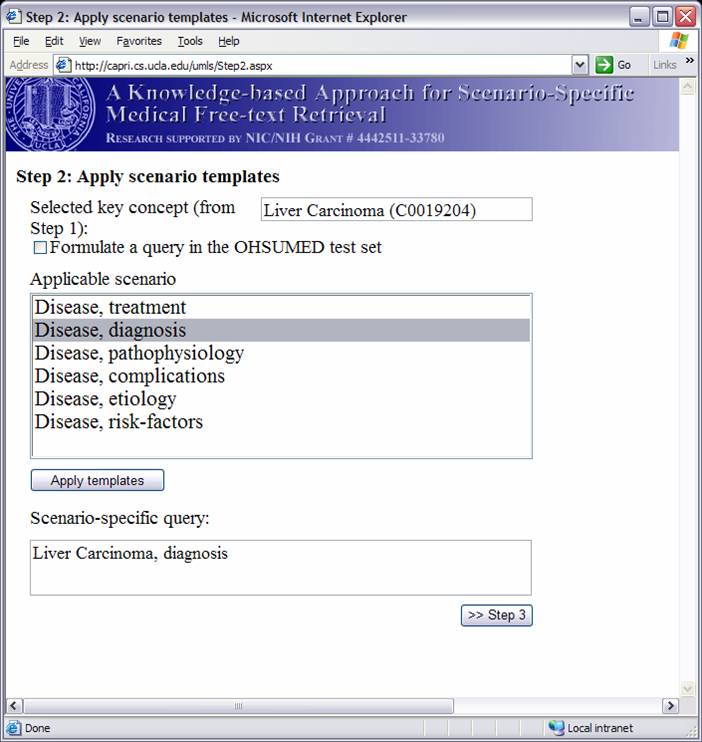 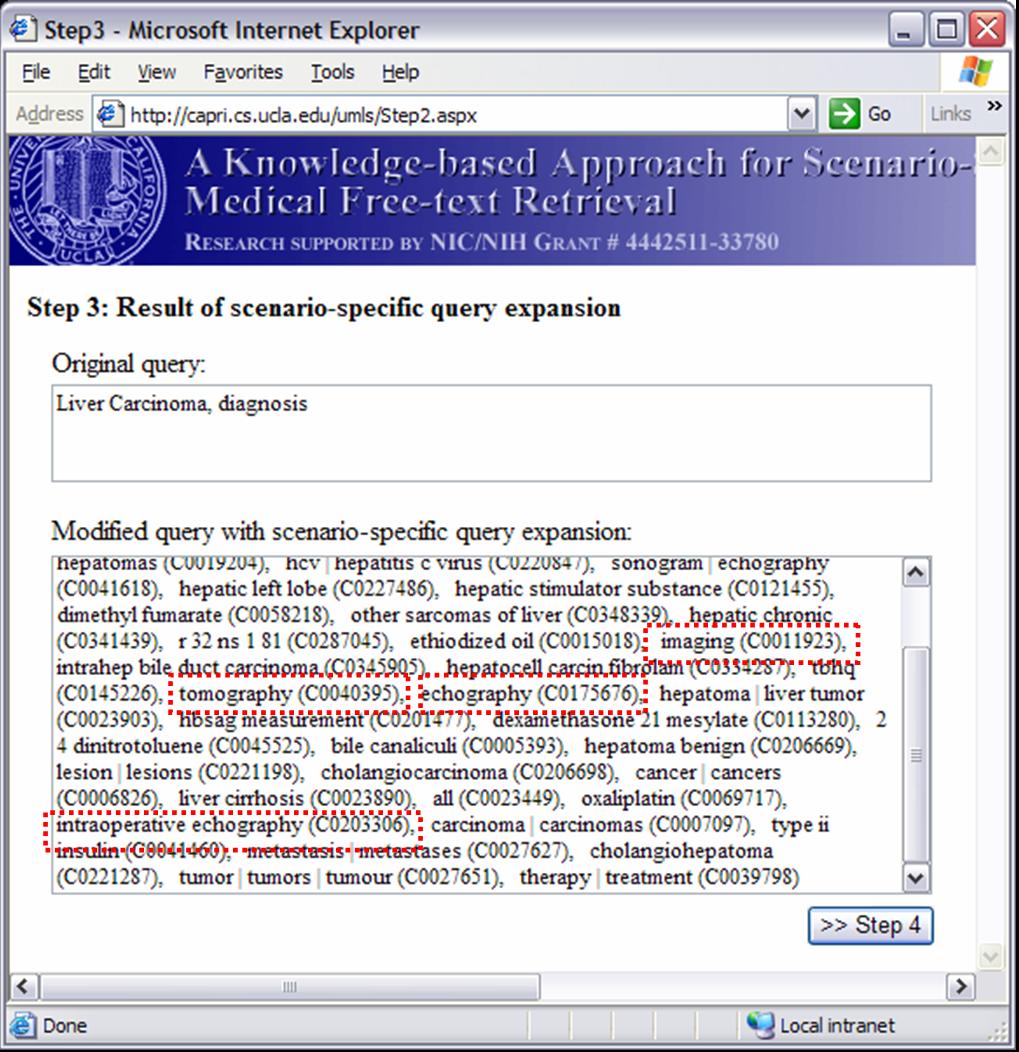
  Related Papers:
Presentation / Demonstration:
|
|
Powered by CoBase Research Group Last updated on July 19, 2006 |